Data Mesh vs Data Lake vs Data Warehouse
Data Mesh, Data Lake, and Data Warehouse solve different problems. The right choice depends on your organisation's scale, governance needs, and data goals. This guide explains where each excels, where it struggles, and why Lakehouse architectures are changing the debate.
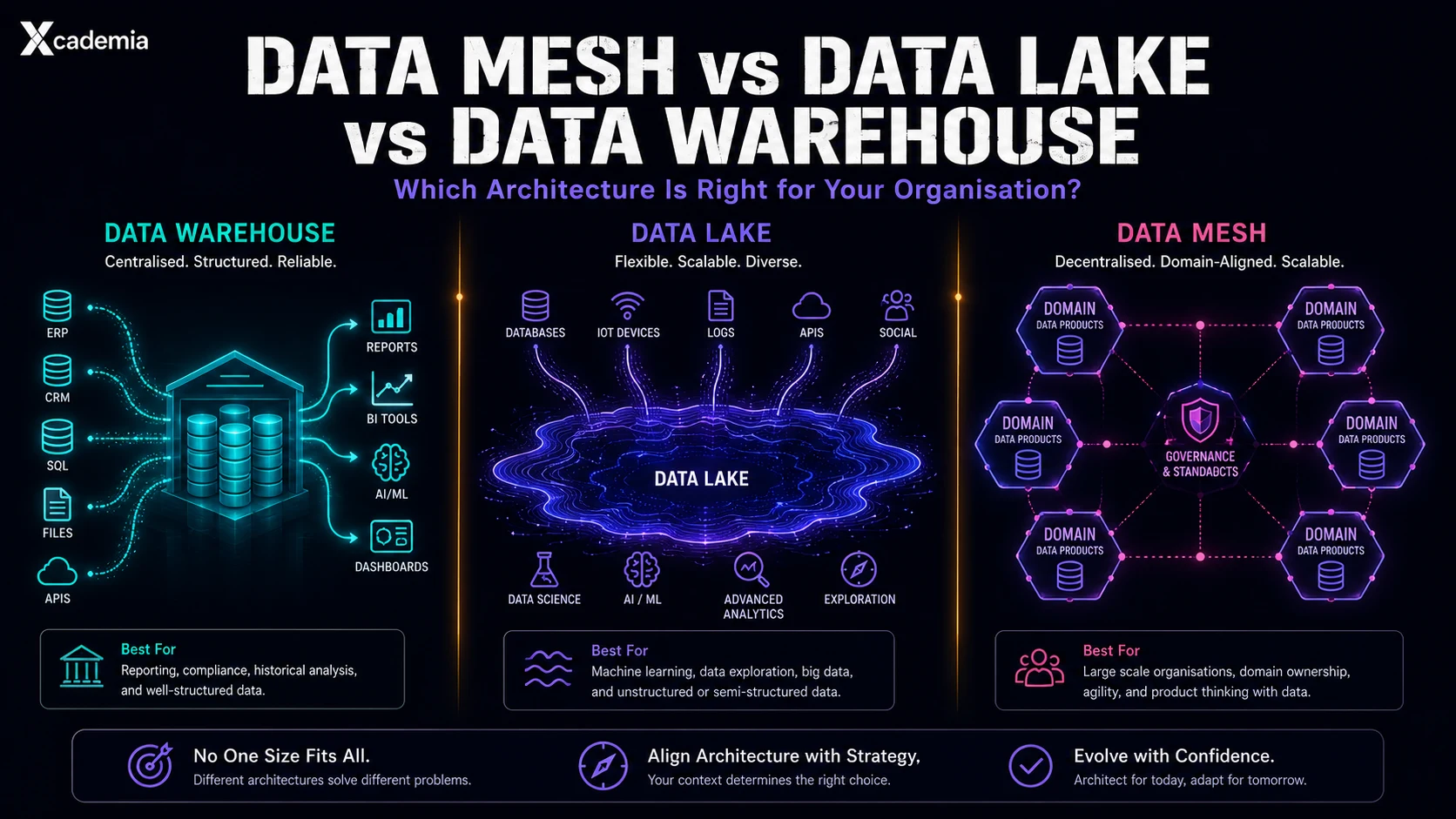
Which architecture is right for your organisation, and why it matters more than the technology choice
Data Mesh is the architecture that every data conference has been talking about since 2019. Data Lake is the architecture that every cloud provider sold organisations on between 2015 and 2022. Data Warehouse is the architecture that has worked reliably for decades and continues to be the right answer for a large proportion of organisations today.
The question that most organisations ask is "which one should we choose?" The more useful question is "which one fits our specific situation?" They solve different problems. Choosing the wrong one is an expensive mistake. Choosing the right one and implementing it poorly is equally expensive. This article explains what each architecture actually is, what problems each solves well, and the decision framework for choosing between them.
The data architecture debate in 2026 has largely moved past the false choice between these three approaches. Most mature data organisations use elements of all three, applied to the contexts where each is strongest. The decision framework is more important than the architecture preference.
Data Warehouse: The Structured Foundation
A data warehouse is a centralised repository of structured, integrated, historical data organised for reporting and analysis. Data is loaded from operational systems through ETL (Extract, Transform, Load) processes, transformed into a consistent schema, and stored in a format optimised for analytical queries. The schema-on-write approach means data is defined and structured before it is loaded.
What it does well
Consistent, governed data: Every report run against the warehouse uses the same definitions, the same transformation logic, the same historical data. The CEO and the CFO see the same revenue number.
Performance for known query patterns: Warehouse architectures (Snowflake, BigQuery, Redshift, Azure Synapse) are optimised for the analytical query patterns that most business intelligence tools use aggregations, filters, joins across large structured datasets.
Compliance and auditability: The controlled transformation pipeline means there is a documented lineage from source data to reported figure. Auditors can trace any number back to its origin.
User accessibility: Business analysts and non-technical users can query a well-designed warehouse with BI tools without understanding the underlying data sources.
Where it struggles
Unstructured and semi-structured data: Traditional warehouse architectures do not handle JSON, images, text, audio, or sensor data well. The schema-on-write requirement means data must be structured before it can be loaded.
Data science and ML workloads: Data scientists need access to raw data, not pre-transformed warehouse data. The transformations that make warehouse data clean for BI may remove signal that ML models need.
Agility: Changing the schema requires coordinating changes across all pipelines, downstream reports, and dependent processes. In fast-moving organisations with evolving data requirements, warehouse schema changes can become bottlenecks.
The data warehouse is the right answer when the primary use case is consistent business intelligence reporting across structured data, compliance and audit requirements are significant, and data quality and consistency matter more than flexibility and raw access.
Data Lake: The Flexible Repository
A data lake is a centralised repository that stores data in its raw format structured, semi-structured, and unstructured at any scale. The schema-on-read approach means data is stored as-is and interpreted at query time. Originally built on Hadoop, modern data lakes run on cloud object storage (AWS S3, Azure Data Lake Storage, GCP Cloud Storage) and are queried through engines like Spark, Presto, or Athena.
What it does well
All data types: Structured transaction data alongside JSON API logs, clickstream data, images, documents, sensor readings, and audio. Everything can coexist in a data lake.
Data science and ML: Data scientists can access raw data in its original form, apply their own transformations, and build models without depending on a warehouse team to pre-transform the data they need.
Low-cost storage at scale: Cloud object storage is significantly cheaper per terabyte than warehouse storage. Data lakes are economically viable for storing years of raw data that may not be queried regularly.
Flexibility: Storing data in raw format preserves optionality. Transformation logic can be applied later when the use case is defined, not before.
Where it struggles
Data quality and governance: Without the discipline of schema-on-write and transformation pipelines, data lakes accumulate inconsistent, duplicated, and unreliable data. The term "data swamp" describes what a data lake becomes without active governance.
Query performance for BI: Raw data in object storage without columnar format optimisation is significantly slower for aggregation-heavy BI queries than a purpose-built analytical warehouse.
User accessibility: Business analysts cannot query a data lake with standard BI tools without significant engineering support. Data lakes primarily serve technical users.
The data lake's promise of storing everything and deciding what to do with it later has frequently produced sprawling collections of ungovernered raw data that nobody trusts. The lake is not wrong as an architecture. It requires as much governance discipline as a warehouse, just applied differently.
Data Mesh: The Distributed Paradigm
Data Mesh, introduced by Zhamak Dehghani in 2019, is not primarily a technology architecture. It is an organisational and ownership model applied to data. The four principles of Data Mesh are: domain ownership (data is owned by the domain teams that produce it), data as a product (domains publish data products that other teams consume), self-serve data infrastructure (a platform team provides tooling that makes it easy for domains to build and publish data products), and federated computational governance (global standards enforced locally).
What it does well
Scale across many domains: In large organisations with dozens of product teams, centralised data teams become bottlenecks. Data Mesh distributes the responsibility for data quality and publication to the teams who know the data best.
Domain autonomy: Product teams can move faster when they own their data products rather than queuing for a central data team to build pipelines.
Data quality at the source: Domain teams who are accountable for the quality of their data products have stronger incentives to maintain quality than a central team that is several steps removed from the operational system.
Where it struggles
Organisational maturity requirement: Data Mesh requires domain teams to take on new responsibilities for data product development, quality, and publication. Teams without this capability will produce low-quality data products that consumers cannot rely on.
Platform investment: The self-serve infrastructure principle requires significant investment in a data platform that makes it easy for non-specialist teams to build and publish data products. This is non-trivial engineering.
Governance complexity: Federated governance requires organisational discipline and enforcement mechanisms that many organisations lack. Without them, Data Mesh produces inconsistent standards across domains.
Data Mesh is the right answer for large, complex organisations with many autonomous product or domain teams where centralised data ownership has become a bottleneck. It is not the right answer for organisations that lack the engineering platform investment and organisational maturity to support it.
The Decision Framework
THREE-WAY COMPARISON TABLE
Data Warehouse | Data Lake | Data Mesh | |
|---|---|---|---|
Primary use case | Consistent BI and reporting | Raw data storage, ML, data science | Domain-owned data products at scale |
Data types | Structured only | All types | All types (published as products) |
Schema approach | Schema on write | Schema on read | Schema per data product (enforced) |
Governance model | Centralised | Centralised (often weak in practice) | Federated with global standards |
Query performance | Excellent for BI | Variable, requires optimisation | Depends on product implementation |
User accessibility | High (BI tools work well) | Low (technical users only) | Medium (via product APIs/interfaces) |
Organisational fit | Any size, clear BI needs | Technical teams, ML-heavy orgs | Large orgs, many autonomous teams |
Implementation complexity | Medium | Medium-High | Very High |
Technology examples | Snowflake, BigQuery, Redshift | S3+Athena, ADLS, GCS+BigQuery | Any of the above + platform tooling |
When to choose a warehouse
Your primary use case is consistent BI reporting used by business stakeholders who are not data engineers. Your data is predominantly structured. Compliance and audit requirements demand consistent, traceable transformations. Your data team is small and centralised.
When to choose a lake
You have significant ML and data science workloads that need raw data access. You need to store large volumes of diverse data types at low cost. Your users are primarily technical. You have the governance discipline to prevent it becoming a swamp.
When to choose a mesh
You are a large organisation with multiple autonomous product or engineering teams. Your centralised data team is a bottleneck. You have the platform engineering capability to build and maintain self-serve infrastructure. You have the organisational maturity to hold domain teams accountable for data product quality.
The Lakehouse option
Most modern data platforms have converged toward a hybrid approach called the Lakehouse: open table formats (Delta Lake, Apache Iceberg, Apache Hudi) on top of cloud object storage that provide ACID transactions, schema evolution, and query performance approaching warehouse performance, while retaining the flexibility and cost economics of a lake. Databricks and Apache Iceberg on Snowflake or BigQuery represent this convergence. For organisations choosing between a lake and a warehouse in 2026, a Lakehouse approach is often the practical answer.
Build Data Engineering and Architecture Capability Xcademia's Core 4 data engineering programmes cover warehouse design, data lake architecture, Databricks and Snowflake platforms, and the organisational and technical dimensions of data strategy. Built for data engineers, architects, and data leaders who need to make and defend architecture decisions. Explore Data Engineering Programmes |
|---|
Ready to go deeper?
Professional Training
Hands-on, mentor-led training aligned with industry certifications.
About the Author
Sharper every day
Daily tutorials, analysis, and career playbooks across all 12 Xcademia disciplines, straight to your inbox. No spam.


